

Overview
Incremental ingestion from Microsoft Dynamics 365 can be difficult when primary keys or update timestamps are unavailable. In a recent enterprise project, we developed a reliable and scalable data pipeline to solve this challenge. The solution enabled daily refreshes in Power BI without data redundancy or performance issues.
Challenges
There were several key obstacles in implementing incremental ingestion from Microsoft Dynamics 365:
- Over 10 million records, with ongoing data growth
- No unique identifiers or modification timestamps
- Azure Data Factory (ADF) could not extract certain fields, especially nested JSON structures
- The ingestion layer had to support full column visibility and integrate with Azure services
To address these, we designed a custom solution that bypassed standard limitations.
Solution
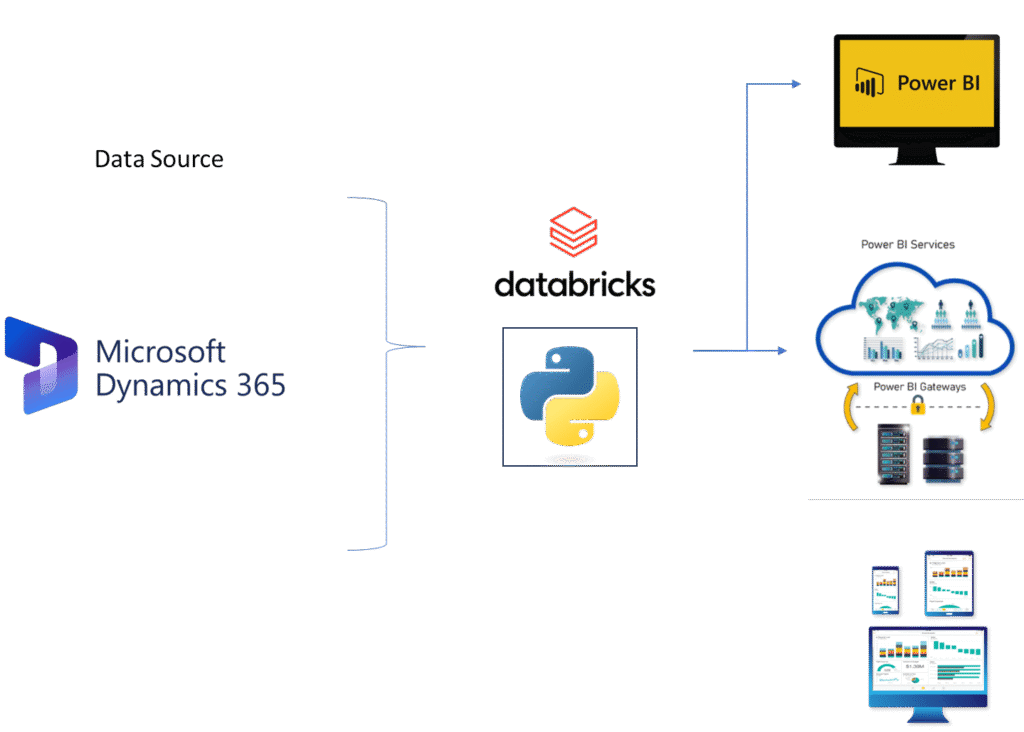
To ensure full control over the ingestion logic, we used Azure Databricks with Python to build a custom ingestion pipeline. This approach made it easier to retrieve and process complex data from Dynamics 365.
Key Components of Ingestion Pipeline
Databricks (Python Notebooks)
We used Python notebooks in Azure Databricks to fetch data via the Dynamics 365 API. All fields—including complex nested ones—were captured and flattened for easy analysis.
Batch Extraction
Data was extracted in segments of 100,000 records to ensure stability and manage load efficiently.
Azure Data Lake Storage (ADLS)
To support scalable incremental ingestion from Microsoft Dynamics 365, batches were stored as Parquet files in ADLS. The latest batch was overwritten in each run to simulate incremental logic, while older batches were retained for auditing.
Azure Data Factory Integration
ADF picked up the latest batch from ADLS and loaded it into Azure SQL Database. This database preserved historical data and appended the latest updates.
Results and Benefits
Our approach to incremental ingestion from Microsoft Dynamics 365 led to:
- Full field extraction, including those not visible in ADF
- Reliable pseudo-incremental loads without keys or timestamps
- Daily refresh support for a dataset exceeding 10 million records
- Scalable, automated architecture integrated with Azure and Power BI
- Improved data visibility and decision-making through enhanced dashboards
Technology Stack Used for Dynamics 365 to Azure Data Ingestion
- Source: Microsoft Dynamics 365 (via API)
- Ingestion: Azure Databricks (Python)
- Storage: Azure Data Lake Storage Gen2
- Orchestration: Azure Data Factory
- Database: Azure SQL Database
- Reporting: Power BI
Key Highlights
- Over 10 million records handled with batch-based logic
- Full visibility into all fields, solving schema issues in ADF
- Simulated incremental ingestion without identifiers
- Modular design ready to scale with future data growth
Next Steps and Links
To explore technical documentation on Microsoft Dynamics 365 APIs, visit the official Microsoft Docs.
Learn more about Azure Databricks and its integration capabilities.
You can also read our related guide on Dynamics Data Load


